
Talk to Your Documents: Build a Real-Time RAG Assistant with Gemini 2.0 Multimodal Live API
Gemini Development Tutorial V6


In this tutorial, we will continue our series on developing real-time applications with Gemini 2.0 and Multimodal Live API. This experimental API is so powerful that it provides developers with the experience of natural, human-like conversations with the ability to handle interruptions. It can process text, audio, and image as inputs at the same time, and it can generate text audio as outputs. By leveraging this API and the performance of Gemini 2.0, we have built quite a lot of real-time web apps and assistants, including a chatbot with a video camera, a screen-sharing assistant, and a drawing canvas assistant. Today, we will build a real-time RAG assistant with Gemini 2.0 Multimodal Live API, which will be able to answer questions about a set of documents. That is, literally, talk to your documents.

You have to agree that RAG (retrieval augmented generation) must be one of the most valuable enhancements of language models. Its context-aware answers prove it is an effective approach to handle questions or tasks about up-to-date information,open-domain knowledge, or proprietary data sources like company sales records, customer service logs, etc.
However, when I tried to examine the documents of Gemini’s multimodal live API, I found that there is no built-in interface for document retrieval like OpenAI Assistant. So, I have to build a custom process to receive the voice audio from the user, retrieve the content from a set of documents, and let Gemini 2.0 generate the answer in audio format based on the document retrieval results. So today, we will build a real-time RAG assistant with both frontend and backend design.
This is the usage experience of our final demo. Currently, we only support PDF file uploads and the basic semantic search technique because it is better to keep the demo simple and easy to understand. However, with the key feature implemented, you can easily extend the application to support more file types and more advanced RAG techniques.
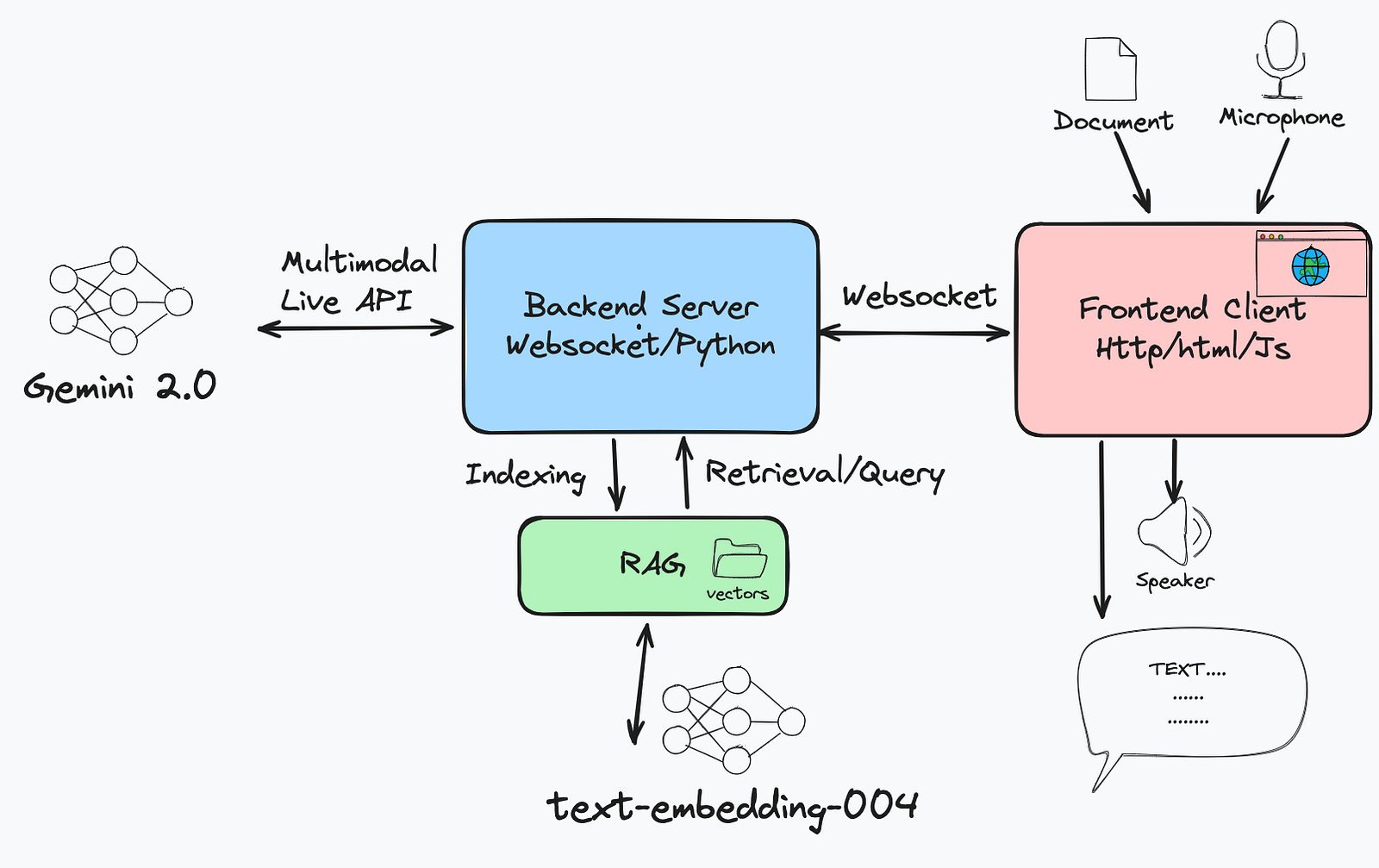
System Architecture
Let’s start with a high-level overview of how the app works.
Like all the previous demos, we have a frontend written in HTML/CSS/JS and a backend written in Python. The front end is a simple web page that allows users to upload a set of documents, display its preview in the window, and manage the user’s voice input and Gemini 2.0’s audio output, plus a text output area to display the model’s response. The pdf file is uploaded to the server and stored on the server side. Meanwhile, the document content will be indexed and stored for later retrieval. There is a function defined to wrap the process of querying the index and return the response, which is exactly the RAG process, and this function is configured as a tool calling to the model’s initialization.
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.