
Use Gemini 2.0 to Build a Realtime Chat App with Multimodal Live API
Gemini Development Tutorial


Google launched Gemini 2.0 with the preview model Gemini 2.0 Flash Experimental, and you must have learned about it from videos and articles. This model has greatly exceeded the performance of its predecessor, Gemini 1.5 Pro, in all the benchmarks, and it’s free for everybody to use, with some limitations in Google AI Studio. If you have experience with Gemini 2.0 or have seen videos about the features in the new version of Google AI Studio, you must be impressed by its capabilities and efficiency in handling complex reasoning tasks, generating reliable code and function calls, with a massive 1M token context window, faster speed and lower latency. While these features are certainly impressive, they are becoming common expectations whenever a new model is released.
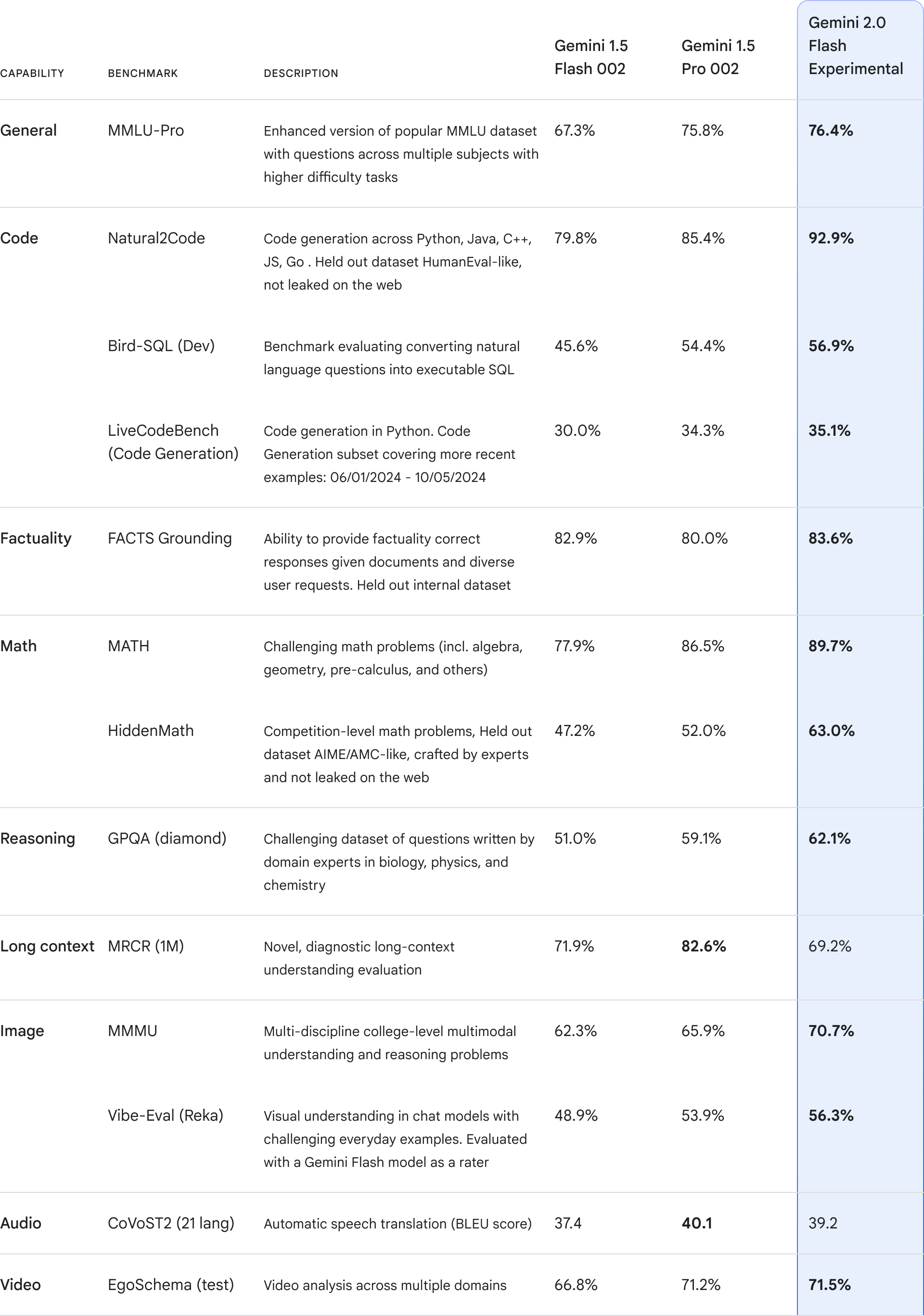
However, what truly sets Gemini 2.0 apart and has the potential to revolutionize the LLM landscape is its advanced multimodal capabilities. The model can now seamlessly process and understand multiple input modalities simultaneously—including text, images, audio, and video—and respond with text or audio in real-time streaming scenarios. This breakthrough makes the AI agents more human-like and helpful for common users.
In this tutorial, I will be focusing on the multi-modal features of Gemini 2.0 and walk you through the official demo app on Google, as well as the code implementation of a native and self-hosted app to showcase how to build your own real-time chatbot with voice & video interaction by using Gemini 2.0 multimodal live API. If you are a developer looking to move beyond initial exploration for a real-world application, this demo project will be a great starting point for you.
Stream Realtime in Google AI Studio
The quickest way to experience the impressive multi-modal capabilities of Gemini 2.0 is to use the demo app on Google AI Studio. Let me walk you through its usage. If you have used the Google AI Studio before, you will find that along with the new model release, the UI has been updated to demonstrate the new features, including the Stream Realtime section for multimodal live with Gemini 2.0 and Starter Apps section that includes three prebuild apps with source code for further demonstrate the details functions inside of the new model including image reasoning, video analysis and native tool calling to Google services.

Click the Stream Realtime button to see what is provided. Then, you can try it out yourself by using the Google AI Studio link with your Google account, which is free at this moment.
Now, I will be trying to use the same Gemini multimodal live API to duplicate the same experience in a native and self-hosted app.
Multimodal Live API
Let’s examine Multimodal Live API. The document states that this product feature is at the experimental stage and might have limited support.
The API is not on the same page as the common Generative API. You also need to note that the API is designed for server-to-server communication, mostly because the protocol is not HTTP but a web socket. so the HTTP client, like your browser, cannot connect directly. As a result of the recommended architecture, you need to implement an intermediate server to handle the WebSocket connection with the API and then forward the messages to a frontend.
When you search on the Gemini documentation, you will find that Google has provided some source code for the multimodal live API in the GitHub repo. Unfortunately, the code is too simple, with only a basic generation process, or too tightly coupled with the Google Cloud project infrastructure. That’s why I decided to implement my own version of the web app at the beginning, which will be a simple chatbot but can be extended to a more complex voice & video interaction app easily for further/existing web apps.
Let’s start with our app implementation.
Code Implementation
The fundamental design of this app is based on the demo project of the Multimodal Live API demo from the Google Generative-AI Repo. For its usage, you can see from the README file that it asks users to connect with the access token and project ID, which comes from the Google Cloud project, which is supposed to host the backend service, and then you can start real-time interaction by text, voice and video. The design is simple but intuitive, so I will follow that, as well as the architecture, excluding authentication.

In conclusion, our app will also be a stack; there will be two web socket connections, one for the client to the server and one for the server to the Gemini API. The code is not that complex, so let’s look at it.

Our focus on this code walkthrough will be on the server side in Python because it’s the main difference from the official Google demos, and it’s key to activating the multimodal live API.
Server-side in Python
First, let’s install the packages. Note that you need to install the new Google generative AI SDK google-genai instead of the legacy one.
pip install -U -q google-genaiIn code, import the necessary packages and load the API key from the environment, defining the model.
## pip install --upgrade google-genai==0.2.2 ##
import asyncio
import json
import os
import websockets
from google import genai
import base64
# Load API key from environment
os.environ['GOOGLE_API_KEY'] = ''
MODEL = "gemini-2.0-flash-exp" # use your model ID
client = genai.Client(
http_options={
'api_version': 'v1alpha',
}
)The genai.Client is instantiated with the configurations. Here, we use the v1alpha version, and this client is the main interface that interacts with the Gemini API for later use.
The next method is the core logic gemini_session_handler. In this function, we will handle the WebSocket connection with the client, forward the messages to the Gemini API, and then receive the response and forward it back to the client. All these communications are based on the WebSocket protocol, so they are all asynchronous, which can be interrupted, reconnected, and restored; these are the key enablers of the real-time behaviour.
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.