
Upgrade Your Gemini Realtime Assistant with Live Illustrations Using Nano Banana
A Quick Tutorial for Development with Gemini Live and Nano Banana Models


Imagine an AI assistant that doesn't just tell you what to do, but shows you. An AI companion that can look at your screen, listen to your questions, and answer via voice channel, and then draw arrows, circle important elements, and highlight key information on an illustration board to guide you. This is much more than a chatbot; it's a real-time, interactive tutor.
This article will show you how to build the backend for such an assistant. It uses a powerful new image model, “Gemini-2.5-flash-image-preview, “ to provide live visual feedback alongside its spoken answers, which is enabled by the Gemini Live API.
Here are a few examples of how the assistant works. The accompanying video will show these demos in action.
a. Web Surfing Support
Now I need help analyzing a list of YouTube channels. The assistant acts as a surfing support.
b. Photopea Online Editor: A Software Guide
The assistant acts as an interactive guide for the Photopea photo editor.
Introducing Gemini 2.5 Flash Image (aka "nano-banana")
The key to this project is a new image model from Google, officially named Gemini 2.5 Flash Image (also known as nano-banana). This model was designed to provide developers with more powerful creative control and higher-quality images than previous versions.
Its most important feature for our project is its ability to perform targeted transformations using natural language. This means you can give it an existing image, like a screen capture, and tell it exactly what to change. You can ask it to "blur the background," "remove a person from a photo," or, in our case, "draw a blue arrow from the File menu to the Save button." The model will perform that specific edit while leaving the rest of the image untouched.
The model is also very good at maintaining character consistency, which is useful for storytelling applications where a character needs to look the same across many different scenes. This level of precise, instruction-based editing is what makes a live, AI-powered illustration board possible.
Block Diagram
The system uses a multi-model pipeline. Each model does a specific job.
This ability to make reliable edits is what makes our live illustration board possible.
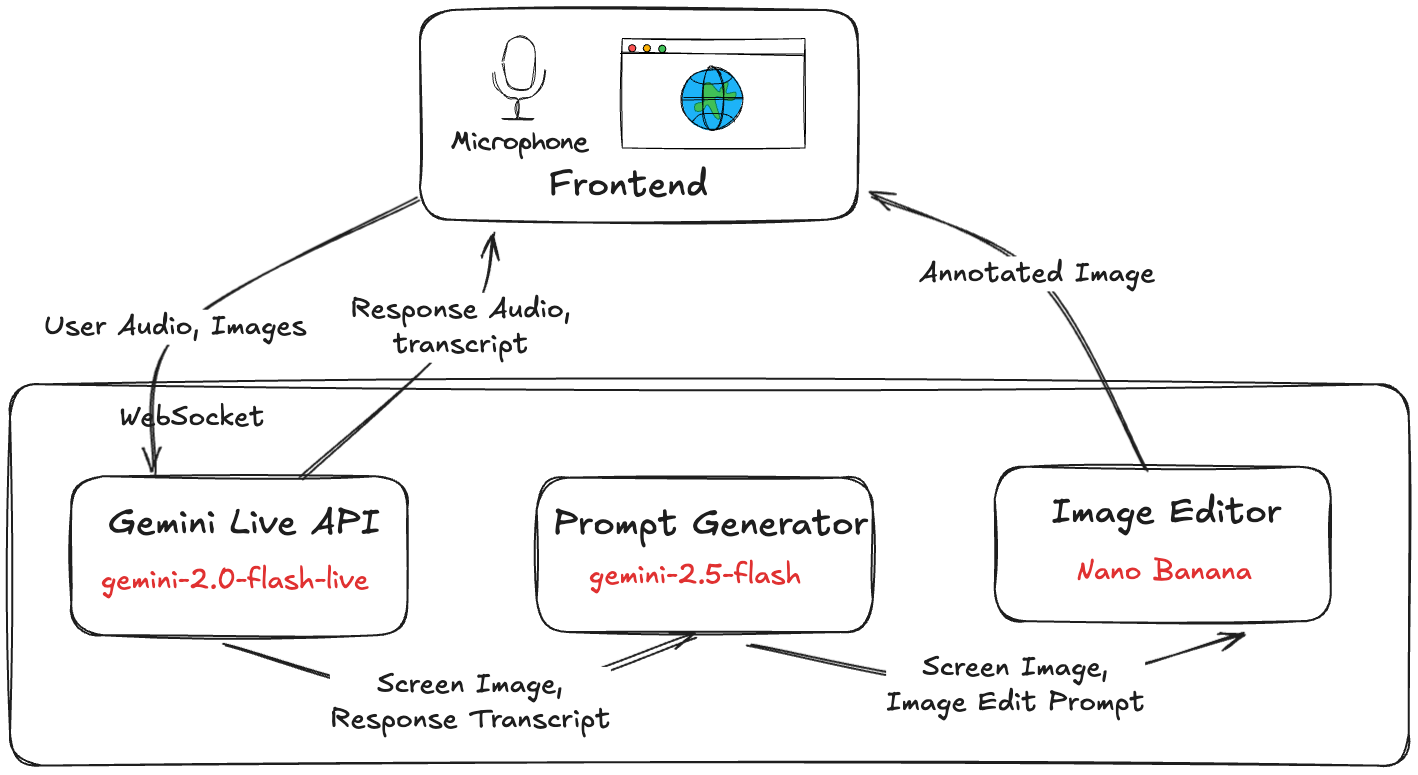
This diagram shows the flow of information in our system. It all starts with the user's browser, which streams their voice and screen capture to our backend server over a WebSocket. The backend forwards this live data to the Gemini Live model. Gemini Live processes the input and generates a spoken audio response, which is streamed back to the user. It also provides a live text transcript of both the user's speech and its own response.
Once the assistant's turn is complete, our backend takes the finalized transcript and the original screen capture from that turn and sends them to the Prompt Generator model. This model's job is to create a simple, text-based instruction for the image edit. Finally, this instruction, along with the original screen capture, is sent to the Image Editor model, which creates the annotated visual. This final image is then sent back to the user's browser to be displayed on the illustration board.
How the Frontend and Backend Communicate
Communication happens over a single WebSocket connection. The messages are simple JSON objects.
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.