
Llama 3.2 Vision Model Tutorial: Build Vision Apps, Multimodal Agents
A Quick Tutorial of Building Apps and AutoGen Agents using Llama 3.2 90B on Fireworks AI


Since the release of Llama 3.2, the open-source LLM community has experienced a significant revolution, especially in vision models and edge computing. In this article, we’ll explore the standout features of Llama 3.2, focusing on its new vision recognition capabilities, and provide practical examples for you developers trying to incorporate these models into your projects, from simple image classification apps to complex multimodal agent programs.
In this tutorial, I will show you how to use the Llama 3.2 vision model to create image extraction apps that recognize the context with structured outputs and how these outputs benefit the multi-agent system by adding this capability.
Llama 3.2 Overview
Llama 3.2 introduces several features:

Vision Models: Small and medium-sized vision language models (11B and 90B parameters) now enable image-based understanding and reasoning.
Edge-Friendly Models: New lightweight, text-only models (1B and 3B parameters) are designed for efficient operation on edge and mobile devices.
Extended Context Length: Smaller models support a context length of up to 128K tokens, enhancing capabilities for on-device tasks.
Ecosystem Support: A broad ecosystem of partners ensures wide accessibility and integration options for Llama 3.2.
Llama Stack: Official Llama Stack distributions simplify deployment across various environments, from single-node setups to cloud and on-device applications.
The 11B and 90B vision models are particularly exciting. They handle tasks such as:
Document-Level Understanding: Interpreting complex documents, including charts and graphs.
Image Captioning: Generating descriptive captions for images.
Visual Grounding: Locating objects in images based on textual descriptions.
These two models serve as drop-in replacements for their ancestors, like Llama 3.1 models, which maintain all text capabilities while adding robust image understanding.
Compared to the two models’ counterparts Claude-3-Haiku and GPT4o-mini, the 90B model benchmark result shows that it is very competitive in image recognition and a range of visual understanding tasks.
Accessing Llama 3.2 with Fireworks AI

If you are curious about how the Llama 3.2 vision model performs but don’t want or can’t afford a high-end GPU to run it by downloading the weights from Huggingface, you can use MetaAI’s partnership Fireworks AI — a platform providing inference API to various language models, including all Llama 3.2 models. Fireworks AI offers a cost-effective serverless to access different models through a unified API or OpenAI compatible API to satisfy the needs of LLM app/agent developers. The Llama 3.2 90B model costs only 0.9 USD/M tokens, and the image normally costs 6400 tokens each, which is approximately 0.0058 USD/img input.

By signing up for an API key, you can make requests to the FireworksAI endpoint and specify the desired model.
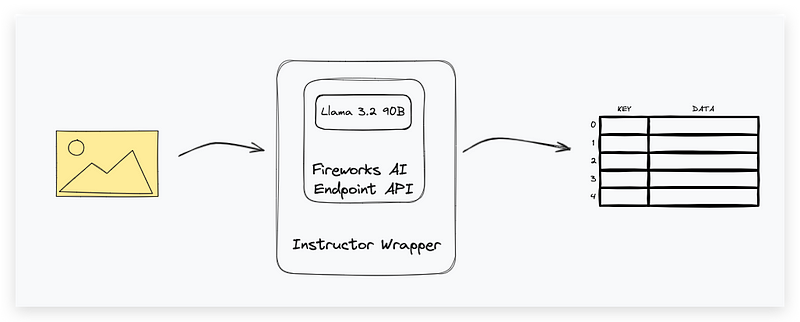
Leveraging Instructor for Structured Outputs

Another critical tool for implementing our demo apps is the Instructor library. This Python library is designed to work with language models to generate reliable structured outputs. By leveraging Pydantic for data validation and schema definition, Instructor ensures that the model’s responses conform to a specific structure, which will simplify the extraction and utilization of information from model responses.
In its API design, Instructor smartly provides a wrapper layer for popular models and model proxies. Such designs will greatly decrease the learning effort for those who are familiar with existing inference APIs. We will see this in detail in the code walkthrough.
Code Walkthrough for Llama 3.2 90B
Let’s dive into code examples to see how Llama 3.2’s vision capabilities can be applied.
Example 1: Analyzing a Movie Screenshot
This application will demonstrate the process of generating basic info from a movie poster or screenshot.
First, install all the Python packages. Here, we install the OpenAI packages to use the compatible Fireworks API to satisfy the construction requirement of Instructor.
pip install openai instructor pydanticImport the necessary libraries:
from openai import OpenAI
from os import getenv
import instructor
from pydantic import BaseModel, Field2. Define a Pydantic model for the expected output
Here, we defined three text items for a movie: name, rate, and review.
class MovieRate(BaseModel):
movie_name: str = Field(..., description="The name of the movie on the poster.")
movie_rate: str = Field(..., description="Your rating of the movie.")
movie_review: str = Field(..., description="Your review of the movie.")3. Initialize the Instructor client using Fireworks API endpoint
This endpoint is compatible with OpenAI API, so we can directly use the client constructor .from_openai() with the redirection of base URL.
client = instructor.from_openai(
OpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=getenv("FIREWORKS_API_KEY")
),
mode=instructor.Mode.JSON
)4. Create a chat completion request with the Llama 3.2 90B vision model and the MovieRate response model for the output structure:
result = client.chat.completions.create(
model="accounts/fireworks/models/llama-v3p2-90b-vision-instruct",
response_model=MovieRate,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "This is a picture about a movie. Please figure out the movie name, rate the movie and review comment."
},
{
"type": "image_url",
"image_url": {
"url": "https://mickeyblog.com/wp-content/uploads/2018/11/2018-11-05-20_41_02-Toy-Story-4_-Trailer-Story-Cast-Every-Update-You-Need-To-Know-720x340.png"
}
}
]
}
],
)
print(result)The message format allows you to upload an image with a text prompt. The image could be as simple as a URL by setting the type to image_url, or a base64 encoded local image.
I attached a screenshot of the Movie Toy Story, and the running result was quite accurate.


Example 2: Extracting a Recipe from a Food Image
The next fun example is to use the model to generate a cooking recipe from an image of a dish.
First, Import the necessary libraries, including
Listfromtyping:
from openai import OpenAI
from os import getenv
import instructor
from typing import List
from pydantic import BaseModel, Field2. Define a Pydantic model for the recipe items (name, ingredients, instructions):
class CookingRecipe(BaseModel):
recipe_name: str = Field(..., description="The name of the recipe.")
ingredients: List[str] = Field(..., description="The ingredients of the recipe.")
instructions: str = Field(..., description="The step-by-step instructions of the recipe.")3. Initialize the Instructor client with Fireworks endpoint:
client = instructor.from_openai(
OpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=getenv("FIREWORKS_API_KEY")
),
mode=instructor.Mode.JSON
)4. Create the chat completion request:
result = client.chat.completions.create(
model="accounts/fireworks/models/llama-v3p2-90b-vision-instruct",
response_model=CookingRecipe,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "This is a picture of a famous cuisine. Please figure out the recipe name and ingredients."
},
{
"type": "image_url",
"image_url": {
"url": "https://www.howtocook.recipes/wp-content/uploads/2021/05/Ratatouille-recipe-500x500.jpg"
}
}
]
}
],
)
print(result)Here is the result from a picture of a dish from Ratatouille:


Integrating Llama 3.2 Vision with AutoGen
For a more complex application, we can integrate Llama 3.2’s vision capabilities into a multi-agent system using AutoGen. So, let’s see how to create a multimodal agent in the AutoGen framework that can extract and analyze images.

{kind=link}