
How to Fine-tune the Llama 3.2 for Reasoning Capabilities at Lowest Cost
A Quick Tutorial on Training LLMs by using UnSloth


If you have used OpenAI’s o1-preview model, you might be surprised by the highest response quality among all the top-class models. The o1 series models are designed to spend more time thinking through problems before responding, leading to more accurate and thoughtful answers, which are mainly contributed by its intermediate reasoning process. In OpenAI’s tests, this reasoning-focused approach has shown impressive results, for example, when gpt-4o solves only 13% of the math exam problems correctly, the o1-preview model can get 83% correct. Therefore, it’s easy to conclude that a model trained with reasoning steps can perform much better in solving complex problems, particularly in science, math, coding, and engineering.
In this tutorial, I will show you the entire training process of the very small model llama-3.2-1B using a LoRA framework — Unsloth, and with the help of a dataset that contains 20k questions/responses containing a detailed chain of thought. As a result, you will see even such a small model can make basic reasoning steps and perform much better in “thinking,” “explaining,” and “correcting” itself in a structured way.
To be more practical, this tutorial will also consider the cost of training and inference to find out how to save money by using the powerful LoRA framework (Unsloth), which can reduce the huge usage of GPU memory, as well as 2x faster speed, which reduces the time of GPU machine usage. If your machine is rented from a GPU cloud, you must know how critical the running time reduction is.
Unsloth

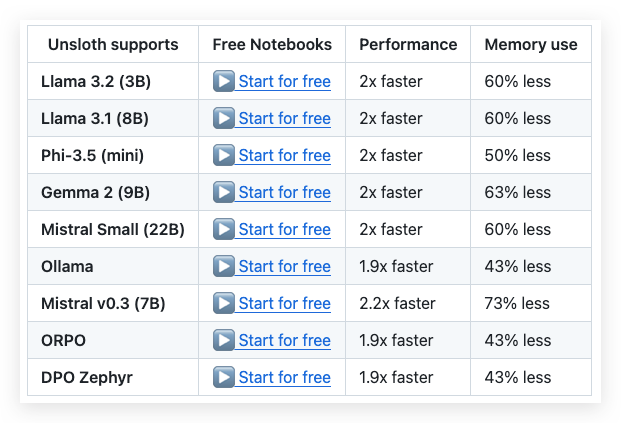
Unsloth is a powerful LoRA framework that can finetune large language models like Llama 3.2, Mistral, Phi-3.5 & Gemma 2–5x faster while using up to 80% less memory. It achieves this through optimized kernels written in OpenAI’s Triton language and a manual backprop engine, without any loss in accuracy since it uses exact methods rather than approximations. The framework supports both 4-bit and 16-bit QLoRA/LoRA finetuning via bitsandbytes, and works on most NVIDIA GPUs since 2018 (requiring CUDA Capability 7.0 or higher). What makes Unsloth particularly attractive for cost-conscious users is that it can reduce GPU memory usage by 43–73%, depending on the model, while providing 2–4x faster training speeds in its open-source version. This means significantly lower costs when using GPU cloud services, as you can train models faster and with less expensive GPU options.
To minimize the technical barriers to entry, Unsloth provides various Colab notebooks to demonstrate the process of fine-tuning with different models and datasets. The demo in this tutorial is also based on the demo notebook of llama 3.2 models. https://colab.research.google.com/drive/1T5-zKWM_5OD21QHwXHiV9ixTRR7k3iB9?usp=sharing
Model and dataset
The model we will use is llama 3.2 1B, which is the smallest model in the Llama 3.2 family and is also considered one of the most powerful models in the portable model zoo. However, it’s still a very limited scale model that can’t perform reasoning steps even with the prompting technique. That’s why, compared to the larger models, it is the best choice for us to see how performance improvement can be achieved by enabling reasoning capabilities quickly. Meanwhile, training such a portable model is really affordable and practical for the average users and businesses.
The dataset we will use is a collection of 20k questions/responses with a detailed “chain of thought” called “Reasoning Base 20k”. https://huggingface.co/datasets/KingNish/reasoning-base-20k
Each entry of this dataset contains a user query, the correct answer, and, most importantly, a detailed step-by-step reasoning process explaining how to arrive at that answer. The problems span various domains, including science, coding, math, and more. The only disadvantage of this dataset is that the number of rows may not be big enough to train a model that can ultimately perform stable reasoning steps for various problems. However, for the purpose of study and research in a cost-effective way, it is more than enough to demonstrate the effectiveness of the reasoning capabilities.
Training process
Now, let’s start the training process. You can either run the training process on your own machine, Google Colab Notebook, or on a cloud GPU service. In this training tutorial, I recommend using the on-demand GPU cloud from Novita.ai, which provides the low-cost rental of NVIDIA GPUs, including RTX 4090, RTX 6000, and A100. You can just use one click to start the server and one click to stop the server to prevent unnecessary costs. Meanwhile, your data and system environment can be saved for up to 7 days at a very low price, which is really flexible and efficient. Here I use the RTX 4090 for training. Using the template of Pytorch 2.2.1, click the Deploy button and wait for a few seconds; your GPU server will be ready.
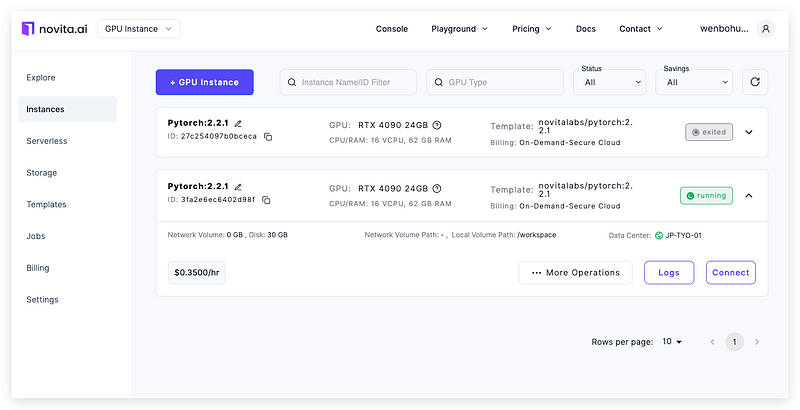
Remotely ssh to the server. First, we need to install the latest version of the Unsloth framework by running the following command:
pip install unsloth “xformers==0.0.28.post2”
pip uninstall unsloth -y && pip install - upgrade - no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"In the source code of training, we need several steps before the training starts:
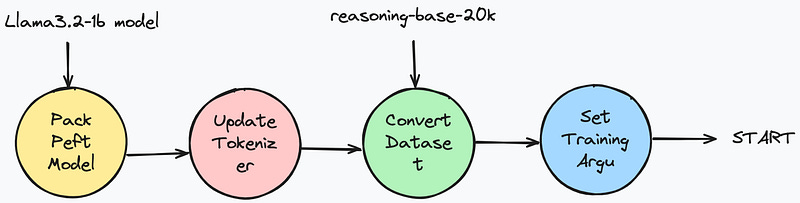
1. Pack a Peft LoRA model based on the base model llama 3.2 1B by using unsloth’s FastLanguageModel class, which can potentially save 30% of the VRAM and fit 2x larger batch sizes as a benefit.
2. Update the tokenizer with a custom reasoning template, and use this tokenizer to transform the original dataset.
3. Set up the training arguments and trainer, where we will maximize the usage of our GPU resources.
4. Start the training and save the model at the end.
Step 1 — Pack a Peft LoRA model
## Pack a Peft LoRA model based on the base model llama 3.2 1B ##
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = False # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-1B-Instruct", # or choose "unsloth/Llama-3.2-1B-Instruct"
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)Here we use the Unsloth’s FastLanguageModel class to load and pack the original llama 3.2 1B model to an optimized Peft LoRA model. You can change load_in_4bit it to True to reduce VRAM usage further. Other parameters can be set to the recommended values by Unsloth for necessary optimizations.
Step 2 — Update the tokenizer and transform the dataset
The original tokenizer of the Llama 3.2 1B model is not designed for the reasoning template, so we need to follow the basic Llama 3.1/3.2 template to add an additional role and message for “reasoning” into the format of the chat template in the tokenizer.
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.