
Hot Update! Build a Realtime Screen Sharing Assistant with VOICE and TEXT by Gemini 2.0
Gemini Development Tutorial V4


In our previous tutorials, we explored the capabilities of the Gemini 2.0 Multimodal Live API, including real-time interaction through text, voice, and camera and screen sharing. I’m happy to see that those tutorials have helped the community and developers start their own projects.

However, a critical issue still prevents real-world application implementation: the inability to provide both real-time text and audio responses concurrently. Even the response_modality parameter in the library can be set to a list of Audio plus text, but that setting does not work as expected, and only an error is thrown out.


As I’ve mentioned before, the Gemini multimodal Live API is still in an experimental stage, so it is still unknown whether or when such an issue will be handled as a requirement. As a channel of development enthusiasm, we should not wait for official support but instead find a way to make it work.
As a reminder, Google AI Studio’s ‘Stream Realtime’ feature lets you experience the multimodal nature of Gemini 2.0 by getting both text and audio output. When text transcription displays in the proper rhythm with the audio stream, it's quite smooth. Google has definitely used some integrated components to make this work, but they have not released it for public use yet.
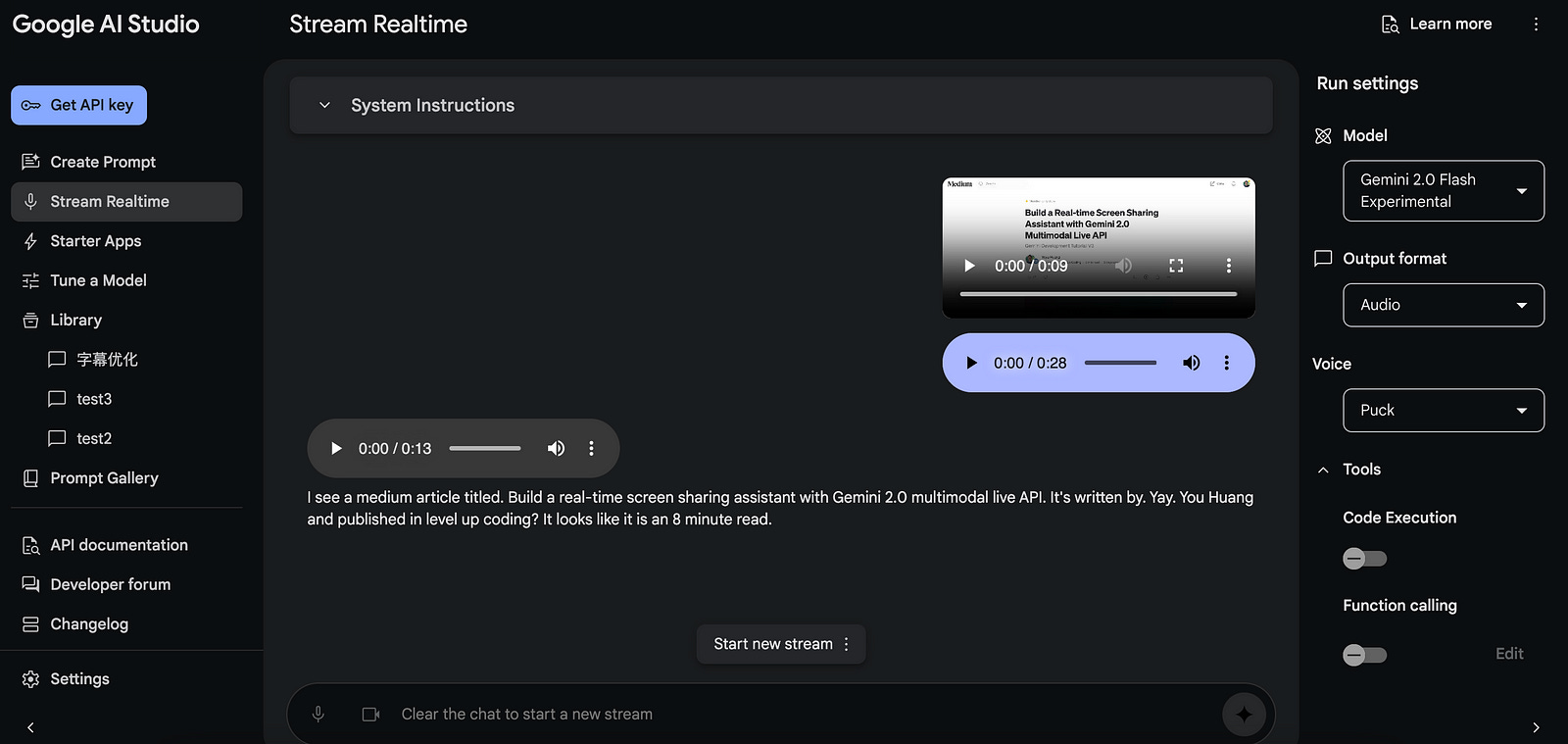
So, in this tutorial, we’ll address this limitation with a new transcription approach and enhance the multimodality by providing both readable transcriptions and audio feedback to implement the real-time screen-sharing assistant. As a reminder, this tutorial will focus more on the core implementation of voice+text output, especially the backend server, so the entire screen-sharing process is implemented with the Gemini 2.0 Multimodal Live API in our previous articles if you haven’t seen it yet and want to know especially the details of the frontend design, please check it out. You can also read this tutorial to see how the key features of text + audio improvements in the backend server are improved and copy the frontend code from my GitHub repository directly.
Let’s get started.
System Overview
First, let’s take a look at the overall structure and data flow of the project.
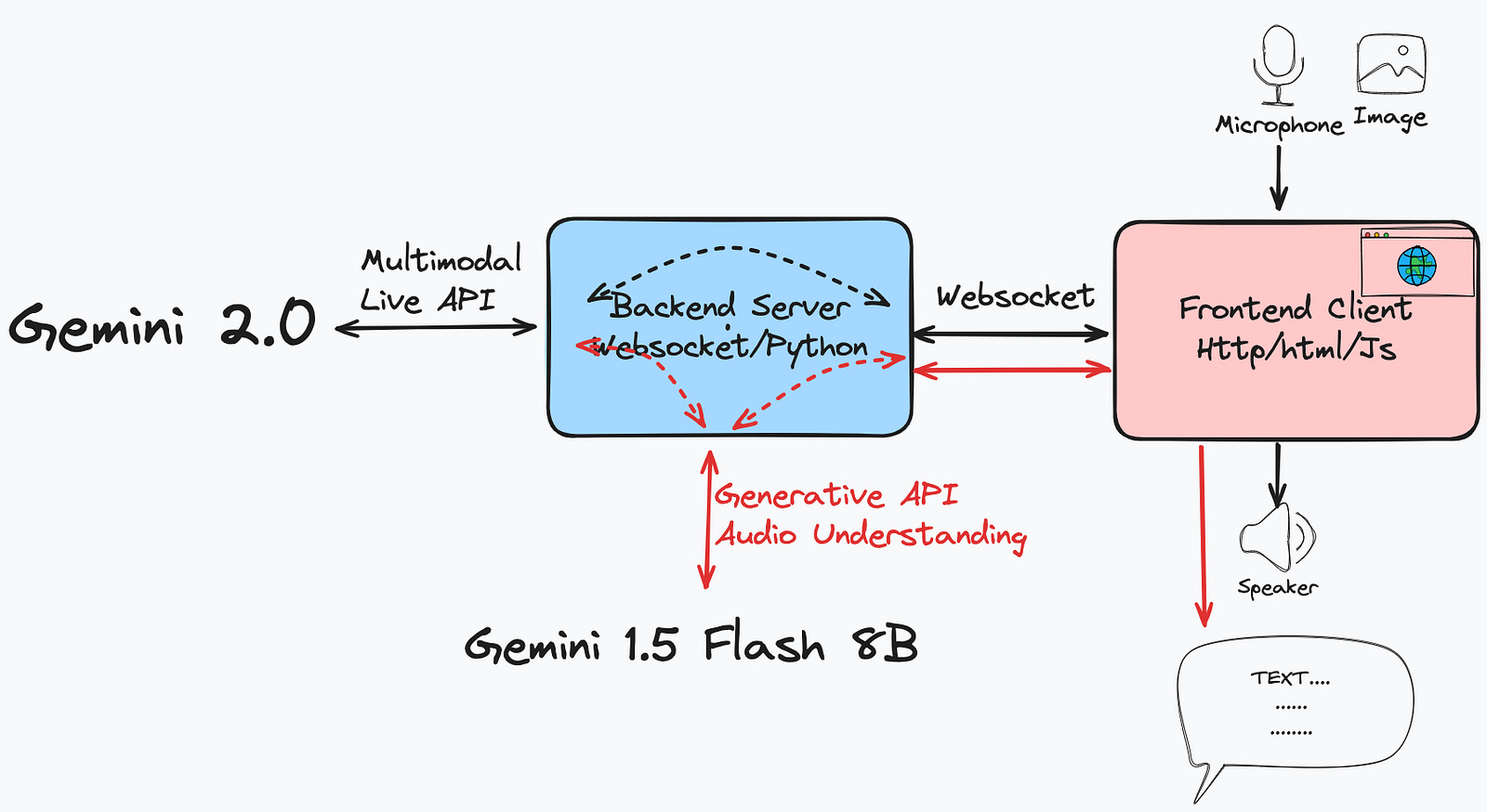
The application uses two Gemini models in a streamlined process. First, the client sends visual and audio input to the server. The server then uses Gemini 2.0 Flash for real-time audio streaming generation. Next, the server transcribes this audio into text using the Gemini 1.5 Flash 8B model. Finally, the server sends both the audio and text back to the client for user output. This ensures the user receives both the audio and its transcript for a complete multimodal experience.
We use two different models because the Gemini 2.0 Flash model is designed for multimodal audio streaming, while the Gemini 1.5 Flash 8B model is much more suitable for transcription tasks. It accepts audio input like other Gemini models but provides the highest generation speed and the lowest latency. Although its intelligence is not as high as that of the Gemini 2.0 Flash model, it’s enough for speech-to-text conversation. Most importantly, it’s super cheap.

Using both models, we can ensure that the audio is processed efficiently and the transcription is fast.
Now, let’s take a look at the server code.
Code Walkthrough
First, as always, we need to install the Gemini’s package. This time, you should be careful to install both the production Gemini API google-generativeai and the experimental Gemini Live API google-genai.
pip install google-generativeai google-genai websockets pydubThe google-generativeai is for Gemini 1.5 flash model for text generation of transcription, and the google-genai is for Gemini 2.0 Flash model for multimodal live generation. Install the WebSockets and Pydub packages for audio processing.
## pip install --upgrade google-genai==0.3.0 google-generativeai==0.8.3##
import asyncio
import json
import os
import websockets
from google import genai
import base64
import io
from pydub import AudioSegment
import google.generativeai as generative
import wave
# Load API key from environment
os.environ['GOOGLE_API_KEY'] = ''
generative.configure(api_key=os.environ['GOOGLE_API_KEY'])
MODEL = "gemini-2.0-flash-exp"
TRANSCRIPTION_MODEL = "gemini-1.5-flash-8b"
client = genai.Client(
http_options={
'api_version': 'v1alpha',
}
)Import those packages and load the API key from the environment variable. And define the two models, one for live audio streaming and the other for transcription. Define the client object for the multimodal live generation.
We will use the client to do WebSockets connection and data exchange with the Gemini 2.0 multimodal live API.
async def main() -> None:
async with websockets.serve(gemini_session_handler, "localhost", 9083):
print("Running websocket server localhost:9083...")
await asyncio.Future() # Keep the server running indefinitely
if __name__ == "__main__":
asyncio.run(main())At the bottom of the code, we call the web sockets.serve function to establish a server on a specified port, and this server is the bridge between the frontend client and the Gemini 2.0 multimodal live API. Each WebSocket connection from the frontend client triggers the handler gemini_session_handler.
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.