
Gemini Live API FINALLY Breaks Session Limits! (New updates: Session Resume, Multilingual, Interrupts & Transcription)
A Code Walkthrough for the Exciting Feature Upgrade


Since its initial release, the Gemini Multimodal Live API has offered exciting possibilities for building interactive applications on top of the live model Gemini 2.0. You may remember that I've been actively exploring its potential through various projects, ranging from interactive camera applications to real-time screen-sharing assistants.
However, if you have been working on the Gemini real-time application development for a while, you must be quite annoyed by these certain limitations that are due to its early experimental stage. These include:
Short Session Durations: The 2-minute session limit for voice and image conversations often resulted in abrupt session terminations and loss of conversational context.
Limited Language Support: The initial lack of comprehensive multilingual support restricted the API's global applicability.
Token Constraints: The finite context window could lead to unexpected session closures due to token overruns (32k).
Transcription Overhead: The absence of built-in transcription required developers to implement separate, resource-intensive transcription pipelines (e.g. my implementation with an independent Gemini Flash model to convert audio to text output separately).
Interrupt Control Challenges: The limited control over interrupt behavior made it difficult to synchronize frontend elements and manage audio playback effectively when the user interrupts the current model’s speech.
Newly Updates
Recognizing these challenges, Google has quietly released a significant update to the API, addressing these limitations and paving the way for more practical and commercially viable real-time multimodal applications.
In this tutorial, we'll explore these key enhancements and demonstrate how they can transform your Gemini Live API projects. We'll cover:
Model Name: Specifying the latest model for optimal performance and access to new features.
Voice Types: More characteristic voice options for a more engaging user experience.
Language Voice: Expanding your application's reach with multilingual support.
Interrupt: Implementing controllable interruption capabilities for a more natural conversational flow.
Token Count: Monitoring token consumption for efficient resource management.
Session Resume: Creating persistent handles (saved sessions) that gracefully handle session timeout.
Transcription: Accessing real-time transcriptions for enhanced accessibility and data records.
By the end of this guide, you'll have a clear understanding of these new features and how to leverage them to build more robust and user-friendly real-time multimodal applications.
System Architecture
Let's begin with a high-level overview of the system architecture, which may look quite familiar to you since most of our real-time applications adopt this server-client architecture:
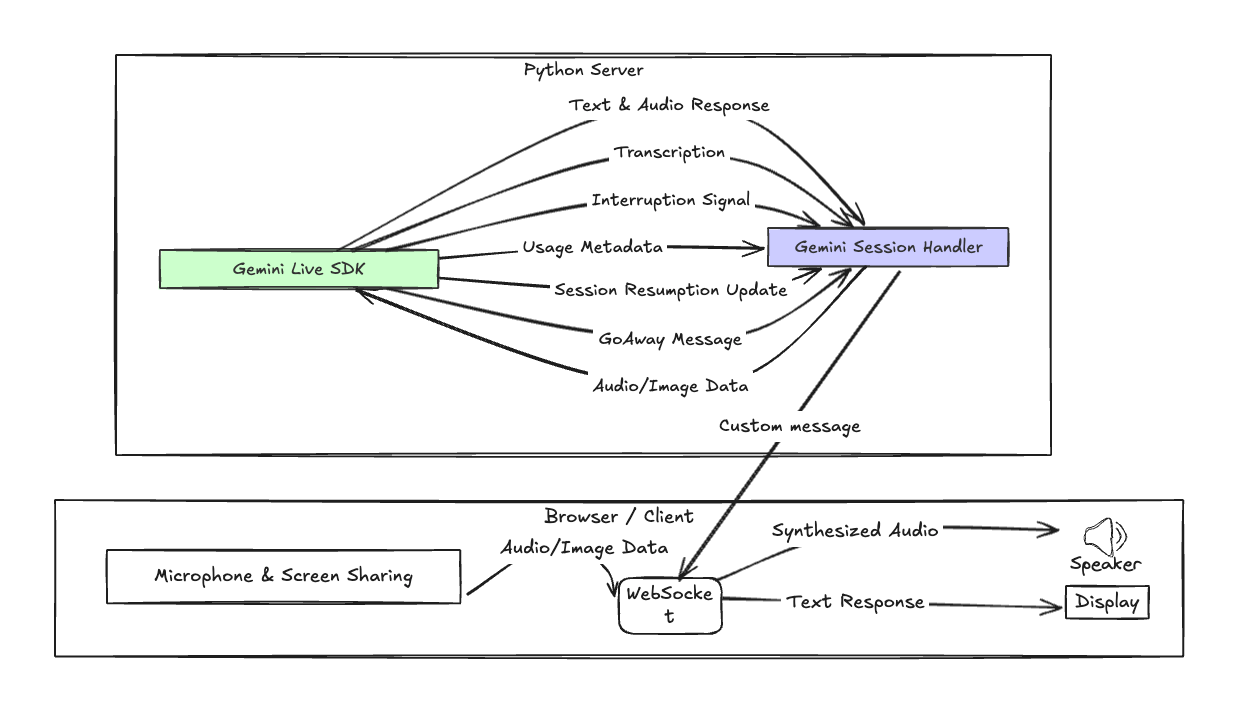
This diagram illustrates the key components and their interactions:
The Client captures user input (audio, video, text) and renders the assistant's responses and transcriptions.
The WebSocket provides a persistent, bidirectional communication channel between the client and the server.
The Server manages the WebSocket connection, orchestrates interactions with the Gemini API, and relays data to the client.
The Gemini API processes the input, generates responses (text and audio), provides real-time transcriptions, and manages sessions, metadata, and other stuff.
