
Do You Know - Function Calling Is Also Available for Open Source LLMs in AutoGen
A Quick Guide to Create Function Agents with Open Source LLMs in AutoGen


Continuing our deep dive into the integration between open-source LLMs and AutoGen, this new tutorial will show you the useful and popular feature “function calling” within the AutoGen framework that significantly extends the capability of agents using open-source language models.
Open-source LLMs shine in their ability to process and generate human-like text at an affordable cost from local deployment or cheap API inference. However, when it comes to accessing real-time data or performing a fixed process to get an answer to a math problem, they hit a snag. The introduction of function calling of OpenAI’s GPT models drastically extends GPT-3.5 and GPT-4 capabilities by enabling them to execute external API calls, which in turn allows access to real-time information and decision-making with contemporary data inputs. To compete with GPT models on this feature, some works are ongoing pushing the performance edge of function calling in open-source language models, including prompting strategies like the instances in LangSmith and fine-tuning like what FireworksAI did.
In this tutorial, I am going to keep developing multi-agent LLM applications in the AutoGen framework and using decent open-source language models with function calls to see whether they can generate and execute a function task like calculation for currency exchange.
AutoGen + OpenSource LLMs
I assume that you have already played with AutoGen for a while to create your own LLM-powered multi-agent conversation app. With AutoGen and its pre-defined conversable agents and patterns, Developers can easily create an AI chat group crowd with different roles to handle complex generation tasks.
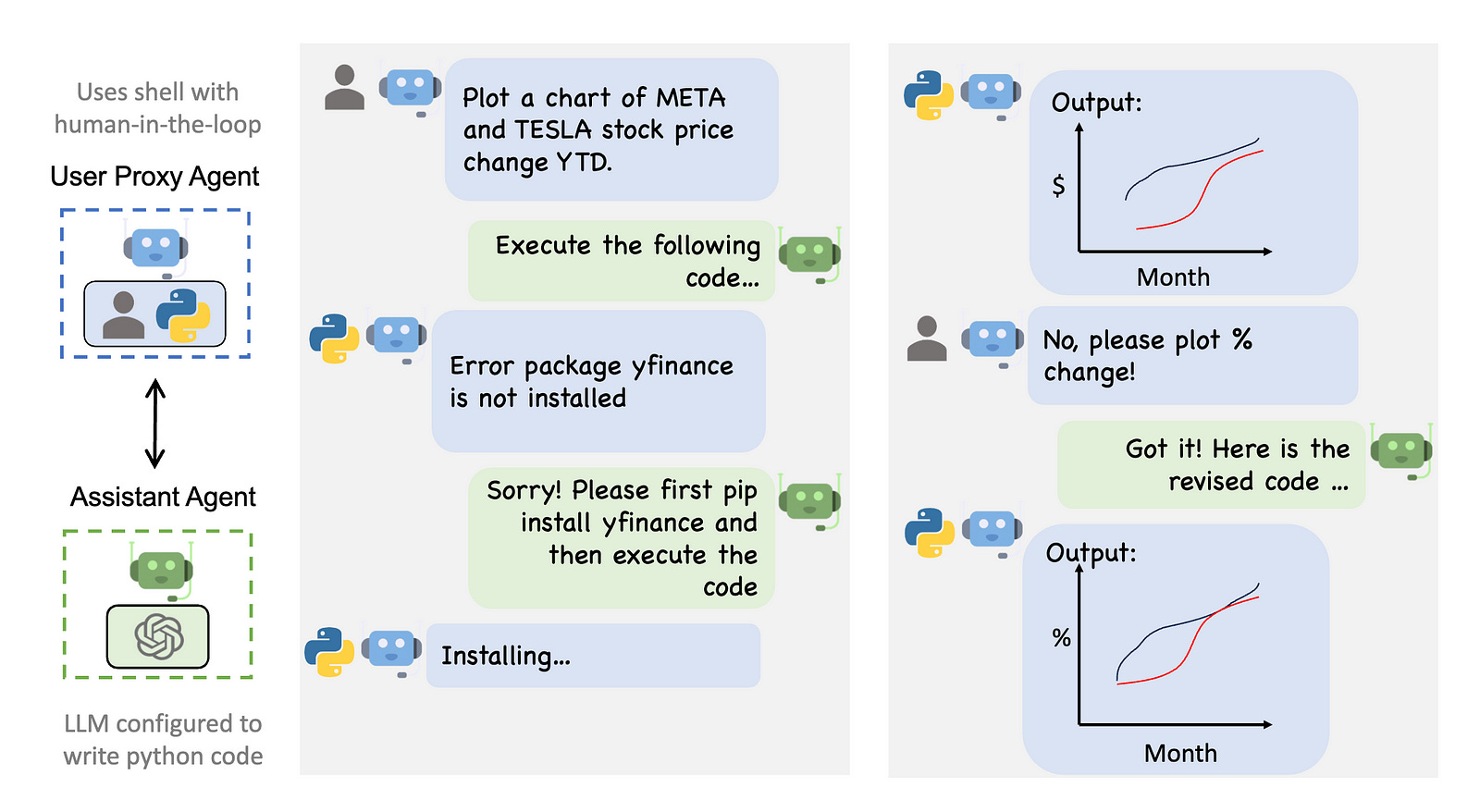
However, AutoGen’s low-level framework only supports OpenAI API, to use open-source LLMs, we should make their inferences compatible with the messaging to OpenAI API. To do that, there are a couple of tools that can help. One type of tool is like vLLM and ollama which construct model inference locally with GPU support and another type uses API inference like FireworksAI without local computational resources but with a little token cost.

In my last tutorial, I showed integrate FireworksAI’s compatibility API into AutoGen, aligning with OpenAI APIs. No need for a dedicated handler. For AutoGen integration, the basic steps are:
Import packages with
!pip install --quiet pyautogen.Define LLM config setting the model from Fireworks AI. In order to use OpenAI-compatible APIs, you have to adjust
base_urlin the OpenAI object and add your Fireworks API Key.Set up the environment variable
OAI_CONFIG_LIST.Construct an AssistantAgent and a MathUserProxy Agent.
Initiate a conversation prompting a math problem for a generation.
import os
os.environ['OAI_CONFIG_LIST'] = """[{"model": "accounts/fireworks/models/qwen-72b-chat",
"api_key": "<FIREWORKS_API_KEY>",
"base_url":"https://api.fireworks.ai/inference/v1"}]
"""
import autogen
llm_config={
"timeout": 600,
"cache_seed": 25, # change the seed for different trials
"config_list": autogen.config_list_from_json(
"OAI_CONFIG_LIST",
filter_dict={"model": ["accounts/fireworks/models/qwen-72b-chat"]},
),
"temperature": 0.2,
}
from autogen.agentchat.contrib.math_user_proxy_agent import MathUserProxyAgent
# create an AssistantAgent instance named "assistant"
assistant = autogen.AssistantAgent(
name="assistant",
llm_config=llm_config,
is_termination_msg=lambda x: True if "TERMINATE" in x.get("content") else False,
)
# create a UserProxyAgent instance named "user_proxy"
mathproxyagent = MathUserProxyAgent(
name="mathproxyagent",
human_input_mode="NEVER",
is_termination_msg=lambda x: True if "TERMINATE" in x.get("content") else False,
code_execution_config={
"work_dir": "work_dir",
"use_docker": False,
},
max_consecutive_auto_reply=5,
)
task1 = """
Find all $x$ that satisfy the inequality $(2x+10)(x+3)<(3x+9)(x+8)$. """
mathproxyagent.initiate_chat(assistant, problem=task1)Evaluation: The Qwen-72B-Chat Model exhibits impressive generation quality and computational efficiency, akin to GPT models but at a lower cost and comparable inference speed.

AutoGen + OpenSource LLMs + Function Call
Fireworks AI introduces a function calling model enabling AI to access APIs for real-time data and adaptive agent actions. Challenges like intent detection and data formatting are addressed by their fine-tuned CodeLlama-34B model, which much outperforms prompt-engineered function calling solutions. Their released evaluation proves its accuracy, adaptability in multi-turn scenarios, and superior intent understanding compared to GPT-4.
The model name is fw-function-call-34b-v0, and you can try it in the playground. Today we are going to implement the function calling with this model to see whether the open-source model can perform well in generating confirmed function calls in JSON format.
Code Walkthrough
Please note that the full support of OpenAI’s function calling (versus Function Calling Assistant) started from AutoGen’s version 0.2.3 by providing decent decorators that wrap the function definition into JSON. Let’s see how to call it.
Step 1 — Upgrade the AutoGen package
pip install pyautogen==0.2.3
or
pip install --upgrade pyautogenStep 2 — Create LLM Config
We will create the LLM configuration including what model to be used. In this case, we use the mode from the Fireworks AI platform. Make sure you input the entire path name for the model, the correct Fireworks API key from your account, and the base_url for the Fireworks endpoint: https://api.fireworks.ai/inference/v1.
import os
os.environ['OAI_CONFIG_LIST'] ='''[
{"model": "accounts/fireworks/models/fw-function-call-34b-v0","api_key": "fN7lqVaajEUNGu2ishDu464TGjtQk2hMrGKyJ6d4WPmyw4GW", "base_url":"https://api.fireworks.ai/inference/v1"}
]'''
import autogen
llm_config={
"timeout": 600,
"cache_seed": 57, # change the seed for different trials
"config_list": autogen.config_list_from_json(
"OAI_CONFIG_LIST",
filter_dict={"model": ["accounts/fireworks/models/mixtral-8x7b-instruct"]},
),
"temperature": 0.5,
}Step 3 — Create two agents
The creation of agents in this example is quite simple. We define an LLM-powered agent chatbot and a user agent user_proxy to execute the code from the generated JSON-formatted function calls. Here we don’t have to write complex system messages to the chatbot to guide its function/parameter generation format.
chatbot = autogen.AssistantAgent(
name="chatbot",
system_message="""For currency exchange tasks,
only use the functions you have been provided with.
Reply TERMINATE when the task is done.
Reply TERMINATE when user's content is empty.""",
llm_config=llm_config,
)
# create a UserProxyAgent instance named "user_proxy"
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().find("TERMINATE") >= 0,
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
)Step 4 — Function & parameter definition
Here comes the critical step to define what are the functions and the parameters that we want the language model to call.
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.