
Clone the Gemini Multimodal Realtime App Locally with Gemma 3, Whisper, Kokoro
An Updated Tutorial for Open-source Solution of Multimodal Realtime Service


Remember that real-time multimodal project we built? The one where we ditched the cloud API limitations of Google’s Gemini and created our own local, real-time assistant using Whisper, Qwen 2.5, and Kokoro? Well, it’s time for a major upgrade. We’re going to make it feel much closer to the responsiveness of Gemini — or maybe even better! This is about achieving a truly natural and intuitive interaction speed, enabling interruptions, and significantly reducing GPU demands.
Let’s recap what we did before, then I’ll show you how we supercharged this project.
Recap: The Open-Source Multimodal Live Solution
In the previous tutorial, we built a system capable of processing real-time audio and images, and creating spoken responses. The key was a three-stage pipeline:
Whisper (small model): For transcribing incoming audio.
Qwen 2.5 VL 7B Instruct model: For multimodal processing — combining the transcribed text with an image to generate a text response.
Kokoro: For text-to-speech, converting the text response back into audio and sending it to the user’s front end.
This approach gave us several huge advantages:
No API Limits: No rate limits, no token counting, no session timeouts. Freedom!
Customization: We could swap out models, tweak parameters, and add support for new languages — total control.
Privacy: All the data stays on our own machine, crucial for sensitive applications.
Cost-Effectiveness: Apart from the initial hardware investment (or cloud GPU rental), there were no ongoing usage fees.
It’s important to note: that this wasn’t about replacing cloud APIs. They have their strengths. This was about providing an alternative — a powerful option for those who need more control, flexibility, and privacy.
We used a WebSocket API designed to be compatible with the Gemini Multimodal Live API, so existing projects (especially front-end code) could be easily reused.
As you can see (and hear!), while it worked, it wasn’t perfect. Here were the key areas we wanted to address:
Response Speed: There was a noticeable delay between speaking and hearing the AI’s response. It didn’t feel like a real-time interaction.
Interruptibility: If you started speaking while the AI was talking, it wouldn’t stop. You had to wait for the entire response, which isn’t how natural conversations work.
GPU Requirements: (You can’t see this in the demo, but it’s important!) The previous version needed a GPU with at least 17GB of VRAM, a barrier for some users.
The Updated Backend Service — Addressing the Challenges
Let’s look at the updated system diagram:
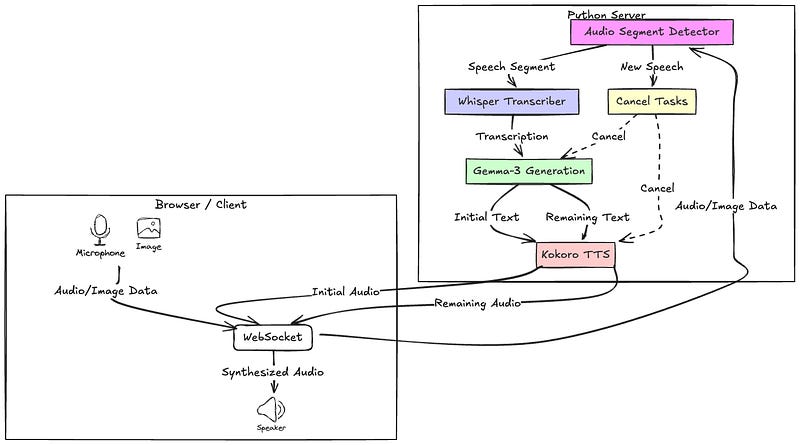
The diagram clearly shows the flow:
Audio and image data travel from the client (browser) to the server via a WebSocket.
The AudioSegmentDetector identifies speech segments and triggers the
WhisperTranscriber.The transcribed text and image go to the
GemmaMultimodalProcessor.Crucially, we see the parallel processing of “Initial Text” and “Remaining Text” by the
KokoroTTSProcessorThe “Cancel Tasks” node, triggered by new speech, demonstrates interruptibility, with control signals (dashed arrows) to stop ongoing generation and TTS.
We addressed the three challenges head-on:
Slow Response Speed: We implemented streaming output and parallel TTS. The Gemma 3 model generates text token-by-token. We immediately synthesize speech from the initial portion of the response using
synthesize_initial_speech(). This happens in parallel with the ongoing text generation. The user hears a response almost instantly. The remaining text is synthesized usingsynthesize_remaining_speech()for higher quality.Lack of Interruptibility: The
AudioSegmentDetectornow continuously monitors for new speech, even during TTS. If detected,cancel_current_tasks()is called, immediately canceling any ongoing generation and TTS tasks. The system then processes the new speech input.High GPU Usage: We switched to the Gemma-3-4B model with 8-bit quantization. This dramatically reduced VRAM usage from 17GB to around 8GB! We also added conversation history to improve response quality.

Unnatural response: Added logic to filter out pure punctuation, single-word utterances, and common filler sounds to prevent the AI from responding to unintentional noises.
Let’s see the new demo in action:
Keep reading with a 7-day free trial
Subscribe to Lab For AI to keep reading this post and get 7 days of free access to the full post archives.