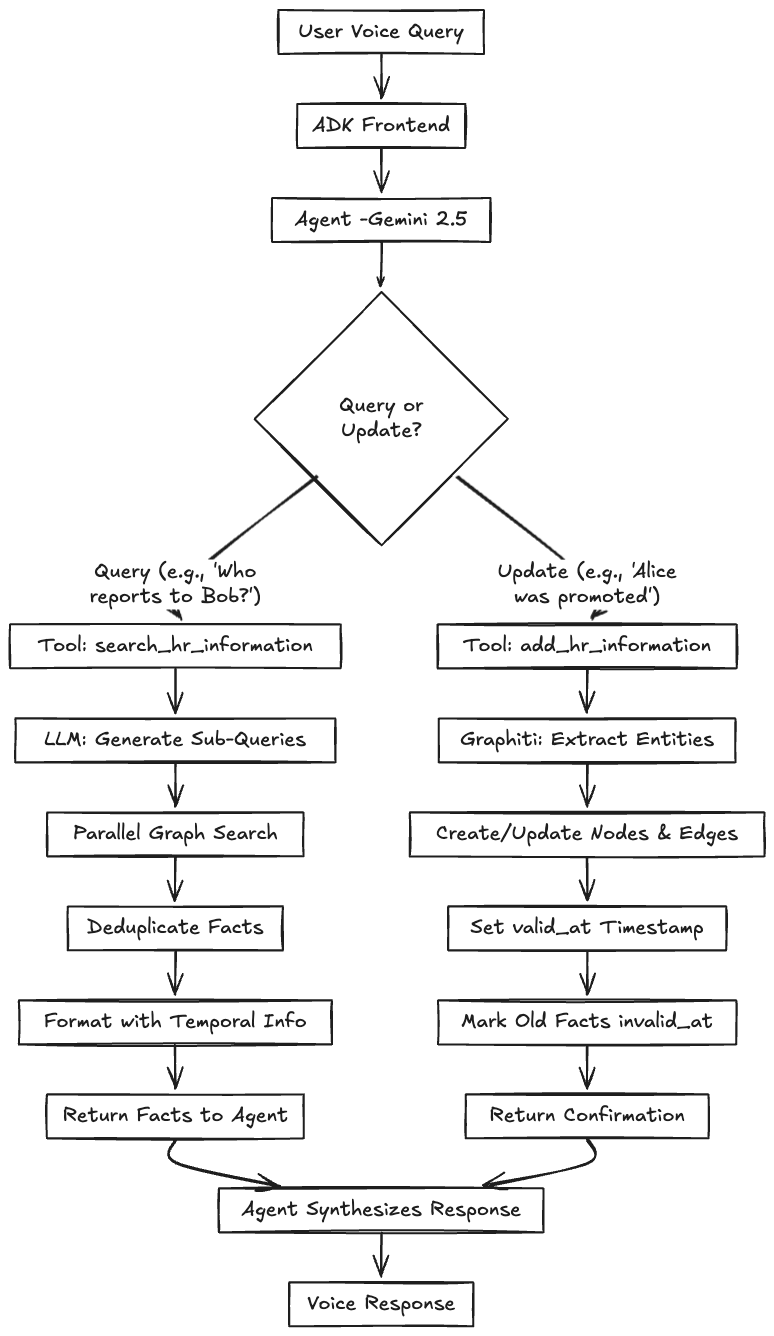
Building Real-Time, Graph-RAG Voice Agents with Graphiti, FalkorDB, and Google ADK


The RAG Dilemma: Vector vs. Graph
RAG system developing teams today face a critical architectural choice: VectorRAG or GraphRAG?
As highlighted in recent industry analysis, the choice depends heavily on your data’s complexity.
VectorRAG relies on embedding-based similarity. It’s fantastic for broad retrieval (”Find documents about policies”) but struggles with multi-hop reasoning. It flattens hierarchical information, making it computationally expensive and unreliable to trace deep logical connections (e.g., “How does a supplier’s ESG violation affect our Q3 financials?”).
GraphRAG explicitly encodes relationships. It allows direct traversal of structured data (Company → Supplier → Violation). It preserves logical connections and enables granular incremental updates—you can update a single edge without re-embedding an entire document corpus.
Why This Matters for Agents
If you are building a Real-Time Voice Agent, you don’t have the luxury of 500ms latency or “hallucinated” relationships. You need:
Multi-Hop Reasoning: To understand that “Alice” is on “Bob’s Team” which works on “Project X.”
Real-Time Updates: If Alice changes teams now, the agent must know now. VectorRAG’s O(n) re-embedding cost is too slow for this.
The Solution
Today, we are building a system that leverages the strengths of GraphRAG to solve these specific problems. We will use Graphiti (for temporal knowledge graphs) and FalkorDB (for sparse-matrix accelerated graph queries) to build a real-time agent that allows for:
Incremental Updates: No re-indexing delay.
Context-Aware Disambiguation: Resolving entities by their connections, not just keyword similarity.
High Speed: Using linear algebra for graph traversal to meet voice-latency requirements.
Firstly, let’s see the live demo to quickly understand how the system works.
The Stack
We will solve the “stale context” problem using Graphiti and FalkorDB, wrapped in the Google Agent Development Kit (ADK) for a native voice interface.
1. FalkorDB: The Speed Layer
FalkorDB is a queryable Property Graph database. Unlike traditional graph DBs, it leverages sparse matrices and linear algebra to execute queries.
It makes graph algorithms incredibly fast. For a voice agent that needs to traverse complex relationships in milliseconds, this mathematical approach is a game changer. It uses the standard Cypher query language, making it easy to adopt.

2. Graphiti: The Temporal Layer
Graphiti sits on top of FalkorDB. It is designed for dynamic environments.
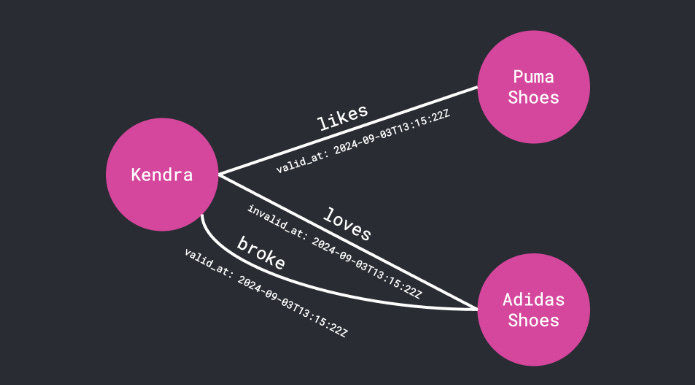
Temporal Awareness: It doesn’t just know facts; it knows when facts are true. It tracks
valid_atandinvalid_attimestamps automatically.Hybrid Retrieval: It combines semantic search (vectors) with graph traversal.

The Scenario: Dynamic Organization Data
To demonstrate this, we will build an agent for a dynamic organization, TechNova, starting from scratch. We will bootstrap the database with an initial state and then simulate real-time updates (like promotions and project changes) to see how the agent handles them.
Initial State: TechNova Organization
We use a setup script (setup_hr_graph.py) to populate FalkorDB. The key insight is that we don’t write search queries or define schemas—we feed Graphiti plain English “episodes” and it extracts entities and relationships automatically.
The Setup Process:
# Define organizational data as plain text “episodes”
episodes = [
{
‘content’: “”“
TechNova is a technology company. Sarah Chen is the CTO.
Michael Rodriguez is the VP of Engineering, reporting to Sarah Chen.
Lisa Wang is the VP of Product, also reporting to Sarah Chen.
“”“,
‘description’: ‘Company overview and executive structure’,
‘timestamp’: datetime.now(timezone.utc) - timedelta(days=365) # Historical data
},
{
‘content’: “”“
Bob Thompson is the Platform Team Manager, reporting to Michael Rodriguez.
Alice Johnson is a Senior Backend Engineer reporting to Bob Thompson.
Alice has skills in Python, Kubernetes, and Docker.
David Kim is a Staff Infrastructure Engineer reporting to Bob Thompson.
“”“,
‘description’: ‘Platform Team structure’,
‘timestamp’: datetime.now(timezone.utc) - timedelta(days=200)
},
# ... more episodes for Backend Team, Frontend Team, Projects, Skills, Compliance
]
# Add each episode to the graph
for episode in episodes:
await graphiti.add_episode(
name=f”TechNova_Org_Episode_{i}”,
episode_body=episode[’content’],
source=EpisodeType.text,
source_description=episode[’description’],
reference_time=episode[’timestamp’], # ← Graphiti tracks when this was true
)
await asyncio.sleep(25) # Rate limit between episodes
What Graphiti Does Automatically:
Entity Extraction: Identifies “Sarah Chen”, “CTO”, “Michael Rodriguez”, etc.
Relationship Creation: Creates edges like
Michael Rodriguez → reports_to → Sarah ChenTemporal Tracking: Each fact gets
valid_attimestamp fromreference_timeSkill/Attribute Linking: Connects “Alice Johnson” →
has_skill→ “Python”
After running the setup script, the graph looks like this:
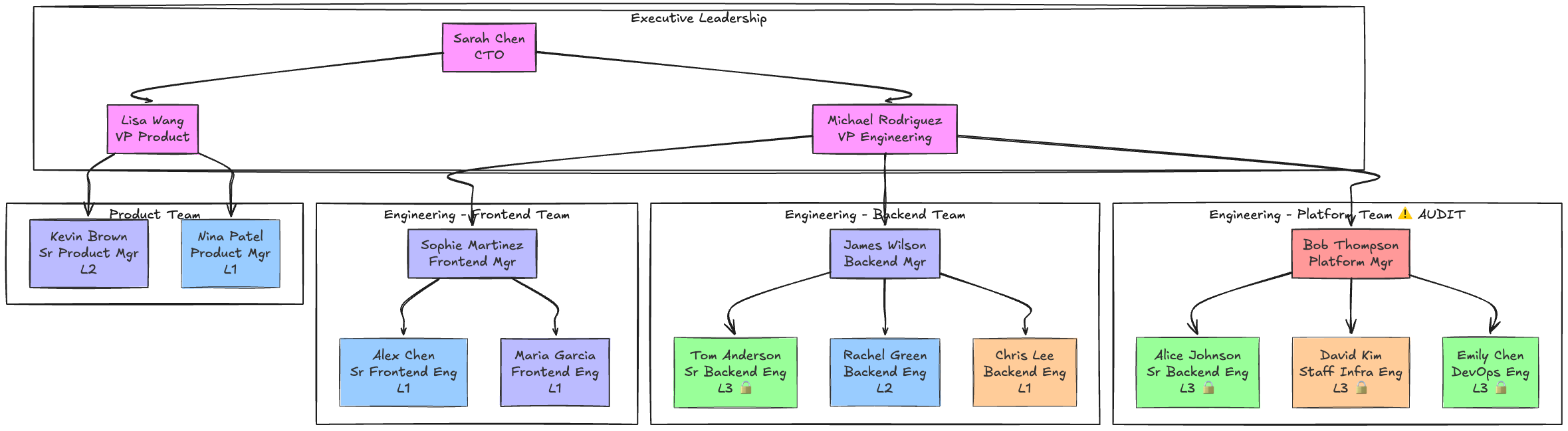
The Complexity: 15 employees, 4 teams, 3 projects, security clearances, audit constraints, and segregation-of-duties rules—all extracted automatically from plain text episodes. This is hard for VectorRAG to traverse reliably, but trivial for a Graph.
Step 1: The Foundation (FalkorDB)
First, we need our graph engine running. We use Docker for this.
# Run FalkorDB exposing ports for the DB (6379) and the UI (3000)
docker run -p 6379:6379 -p 3000:3000 -it falkordb/falkordb
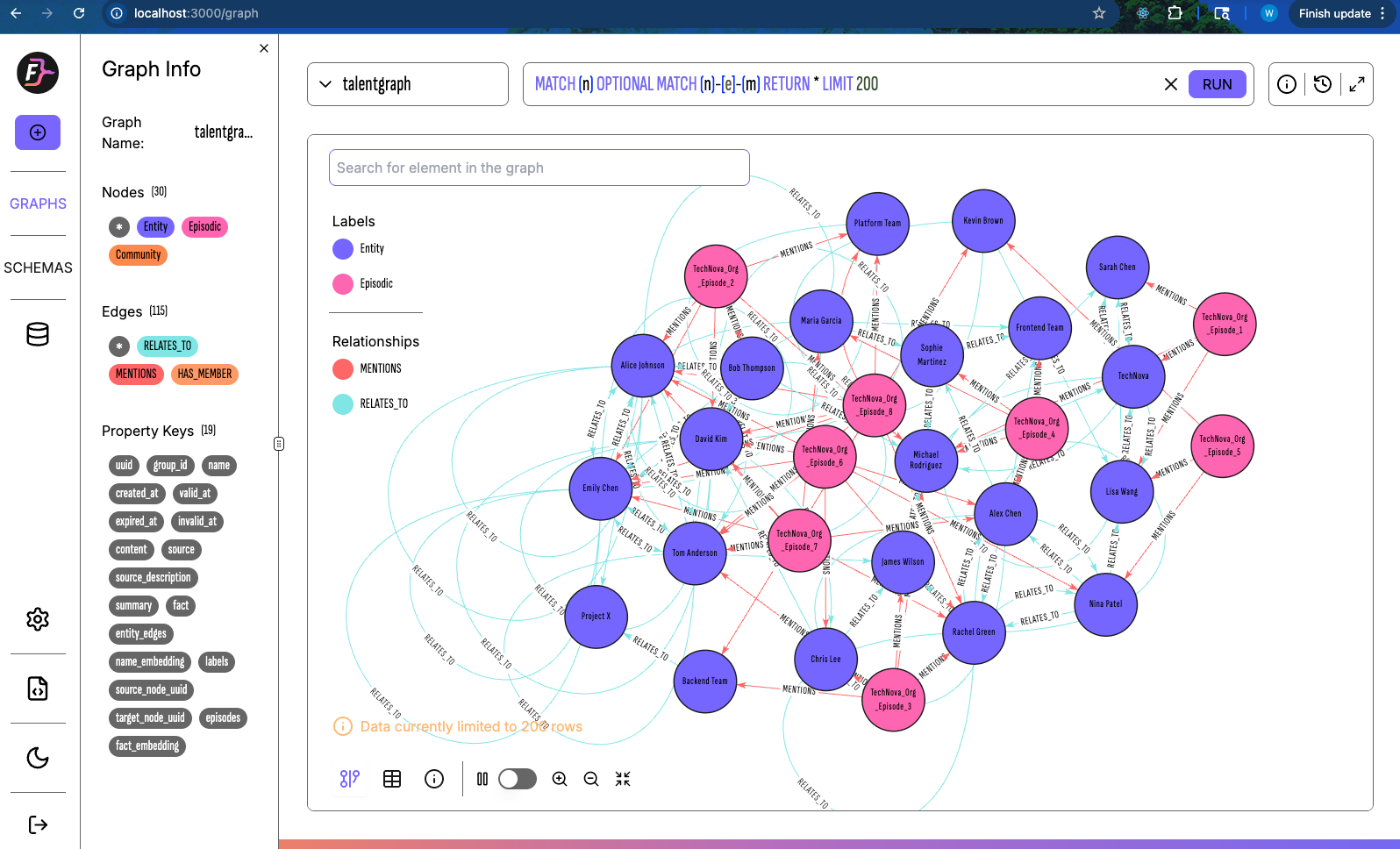
Once running, you can visit
http://localhost:3000
to visualize your graph nodes and edges in real-time.
FalkorDB Quick Test
Before we layer on Graphiti, let’s prove FalkorDB works with a simple Python script. This demonstrates how easy it is to create nodes and edges using Cypher.
from falkordb import FalkorDB
# Connect to FalkorDB
db = FalkorDB(host=’localhost’, port=6379)
g = db.select_graph(’MotoGP’)
# Create nodes and edges
g.query(”“”CREATE (:Rider {name:’Valentino Rossi’})-[:rides]->(:Team {name:’Yamaha’}),
(:Rider {name:’Dani Pedrosa’})-[:rides]->(:Team {name:’Honda’})”“”)
# Query: Who rides for Yamaha?
res = g.query(”“”MATCH (r:Rider)-[:rides]->(t:Team)
WHERE t.name = ‘Yamaha’
RETURN r.name”“”)
print(res.result_set[0][0]) # Prints: “Valentino Rossi”
This simplicity is why we chose FalkorDB. It’s just standard Cypher, but blazing fast.
Step 2: The HR Agent Architecture
Now, let’s build the actual agent. We aren’t just dumping text; we are building a structured organization.
The Data Model
We are simulating a tech company (”TechNova”) with a specific hierarchy:
CTO (Sarah Chen): leads the engineering org.
VPs: Report to the CTO.
Managers: Report to VPs (e.g., Bob Thompson).
Engineers: Report to Managers, belong to Teams (Platform, Backend), and work on Projects (Project X, AI Strategy).
We also track Security Clearances (Level 1-3) and Skills (Python, Kubernetes).
The Agent Workflow
Our agent uses a sophisticated multi-step reasoning loop: