
AutoGen's Full Function UI Powered by Panel
A Walkthrough of AutoGen+Panel Project Ep.2


Following the publication of my previous tutorial on AutoGen+Panel, I was surprised to witness the strong interest it gained from communities. The rising of attention came with a series of requests for more completeness on the chat functionalities, especially the human interaction in the AutoGen conversation process. Now, after a couple of time development, I’m pumped to say that I can now deliver that feature you’ve been waiting for, which allows the user to input messages in response to AI agents’ requests during group chat. Have a quick look at this demo:
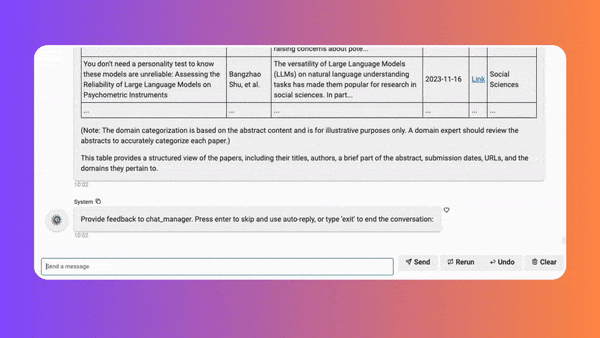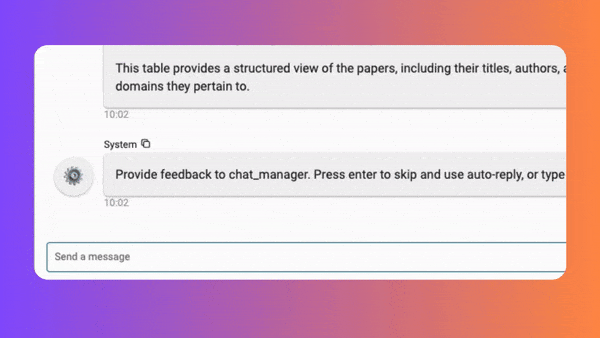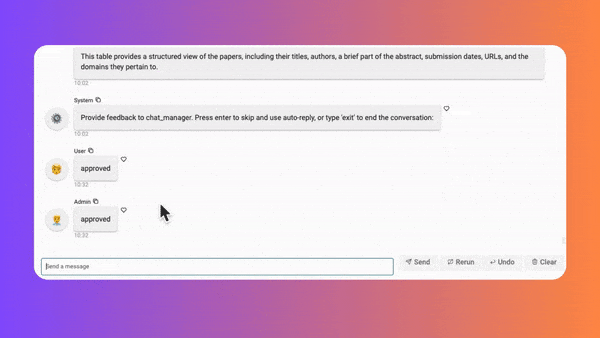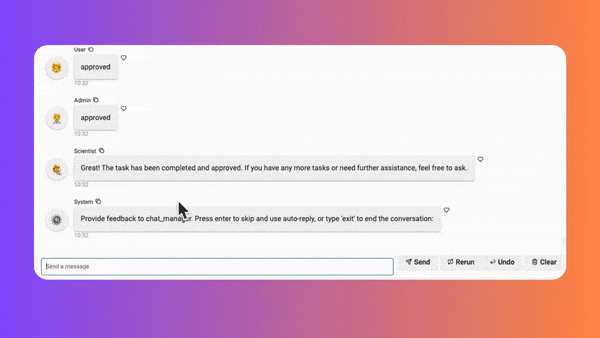
Background
If you have no idea what is my previous tutorial and what is AutoGen+Panel project, here is a quick summary for you.
AutoGen by Microsoft is an LLM development framework for creating automated conversations between multiple AI agents to complete complex tasks autonomously. It was praised for customizable agents and seamless integration with human input. The framework stands out for offering versatile conversation patterns and being compatible with other models and prompting technologies, enhancing agent capabilities. However, I found its output challenging to navigate in the command line, prompting the use of Panel’s new Chat Component to create a more accessible chatbot-style UI. My tutorial demonstrates the development of an integrated Panel UI working with AutoGen, which makes multi-agent conversations and their outputs including code and tables more user-friendly and readable.
This is AutoGen’s original UI

This is the Panel powered UI
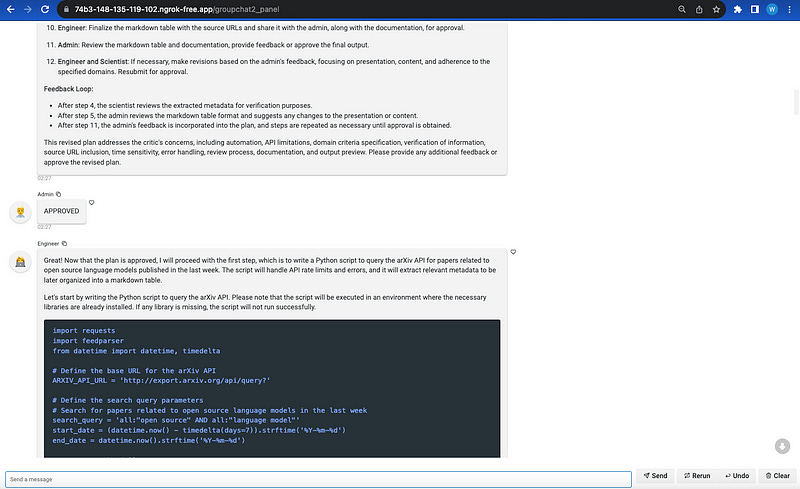
In our last demo of a search chatgroup, there were six agents in the chat group including 2 user proxy agents — Admin (approver for planning), Executor (Python runtime), and 4 LLM-powered agents — Engineer, Planner, Scientist, and Critic. Once you provide a query like a request for a package of recent LLM paper on Arxiv, the agents will start to generate a stetp-by-step context based on the sequence appointed by AutoGen’s core manager.
Leveraging the advancement of LLM and AutoGen’s prompting techniques, there are always revised suggestions made by agents and it’s better for human users to provide approval, decline, termination, or further instructions. Human input can definitely improve the concision, flexibility for users to reach their preferred results, and cost-effectiveness for the application provider as well.
Unfortunately, although we had completed the integration development for AutoGen+Panel to display the entire AutoGen internal conversation progress on a decent Web UI, there was a limitation that the admin agent (User Proxy) should be set as “NEVER” for human input mode. By this setting, the human interaction will be disabled, the responses of the admin agent could only be powered by an LLM or a default auto-reply that users pre-set.
user_proxy = autogen.UserProxyAgent(
name="Admin",
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),
system_message="""A human admin. Interact with the planner to discuss the plan. Plan execution needs to be approved by this admin.
Only say APPROVED in most cases, and say EXIT when nothing to be done further. Do not say others.""",
code_execution_config=False,
default_auto_reply="Approved",
human_input_mode="NEVER",
llm_config=gpt4_config,
)If we set the human_input_mode as “ALWAYS” in our last demo, the UI input will keep blocked even when the conversation requires it, the only way to continue the conversation is to input your message in the terminal console, which is not good, so please follow me to continue development.
Code Walkthrough
In this code demonstration, we will continue our previous project AutoGen+Panel with a GroupChat-Research pattern to integrate human input functionality. Please note that even when I say “continue”, it doesn’t mean that you have to learn from the last article for the fundamental coding, this tutorial will cover all the original source code and their explanation in an efficient way, so you can read this article alone to have quick implementation.
1. Upgrade the dependencies
The key enabler for this UI function is to replace the process of original AutoGen calls from sync to async, otherwise, the UI input can be blocked until the entire conversation is finished.
Fortunately, the recent update from AutoGen has expanded the asynchronous methods, and till the time I wrote this article, most of the new methods we need have not been released on PyPI yet (currently 0.1.14 on PyPI). We should download it from the GitHub branch directly.
pip uninstall pyautogen
pip install git+https://github.com/microsoft/autogen.git2. Setup the agents
let’s quickly repeat what we did for setting up these autonomous agents.
Import the packages and configure:
import autogen
import openai
import os
import time
os.environ["OPENAI_API_KEY"] = "sk-Your_OpenAI_KEY"
config_list = [
{
'model': 'gpt-4-1106-preview',
}
]
gpt4_config = {"config_list": config_list, "temperature":0, "seed": 53}Create the original 5 agents without any changes except the Admin for later steps.
engineer = autogen.AssistantAgent(
name="Engineer",
llm_config=gpt4_config,
system_message='''Engineer. You follow an approved plan. You write python/shell code to solve tasks. Wrap the code in a code block that specifies the script type. The user can't modify your code. So do not suggest incomplete code which requires others to modify. Don't use a code block if it's not intended to be executed by the executor.
Don't include multiple code blocks in one response. Do not ask others to copy and paste the result. Check the execution result returned by the executor.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
''',
)
scientist = autogen.AssistantAgent(
name="Scientist",
llm_config=gpt4_config,
system_message="""Scientist. You follow an approved plan. You are able to categorize papers after seeing their abstracts printed. You don't write code."""
)
planner = autogen.AssistantAgent(
name="Planner",
system_message='''Planner. Suggest a plan. Revise the plan based on feedback from admin and critic, until admin approval.
The plan may involve an engineer who can write code and a scientist who doesn't write code.
Explain the plan first. Be clear which step is performed by an engineer, and which step is performed by a scientist.
''',
llm_config=gpt4_config,
)
executor = autogen.UserProxyAgent(
name="Executor",
system_message="Executor. Execute the code written by the engineer and report the result.",
code_execution_config={"last_n_messages": 3, "work_dir": "paper"},
)
critic = autogen.AssistantAgent(
name="Critic",
system_message="""Critic. Double check plan, claims, code from other agents and provide feedback.
Check whether the plan includes adding verifiable info such as source URL.
""",
llm_config=gpt4_config,
)Now, let’s create the Admin agent which allows human interaction. But before the agent creation, we should provide a custom agent class MyConversableAgent for the admin inheriting ConversableAgent.
import asyncio
input_future = None
class MyConversableAgent(autogen.ConversableAgent):
async def a_get_human_input(self, prompt: str) -> str:
global input_future
chat_interface.send(prompt, user="System", respond=False)
# Create a new Future object for this input operation if none exists
if input_future is None or input_future.done():
input_future = asyncio.Future()
# Wait for the callback to set a result on the future
await input_future
# Once the result is set, extract the value and reset the future for the next input operation
input_value = input_future.result()
input_future = None
return input_valueThe reason for replacing the original UserProxy agent class is that we have to rewrite the async function a_get_human_input() to re-direct the human input from the terminal console to the Panel’s ChatInput widget. Here I use a series of asyncio methods and objects to wait and pass the input messages input_value from the web side to internal AutoGen logic. The use of the call chat_interface.send(prompt, user=”System”, respond=False) is to send a prompt message to the user to notify them for input.

Since we have a valid custom agent class, let’s define the new admin agent by it. Please note that now we should not configure LLM to it and must set the human_input_mode to ALWAYS.
user_proxy = MyConversableAgent(
name="Admin",
system_message="""A human admin. Interact with the planner to discuss the plan. Plan execution needs to be approved by this admin.
""",
code_execution_config=False,
human_input_mode="ALWAYS",
)We can wrap up them to the AutoGen manager now.
groupchat = autogen.GroupChat(agents=[user_proxy, engineer, scientist, planner, executor, critic], messages=[], max_round=20)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=gpt4_config)Important!
In order to ask the system to call a_get_human_input() instead of get_human_input() in its internal logic, a critical step (so far) is to register its parent method a_check_termination_and_human_reply() in the object initial of ConversableAgent. Please be careful with this change as we are changing AutoGen’s source code.
Find the source file in the package autogen/agentchat/conversable_agent.py. By the way, if you do not know where is the AutoGen package in your machine, you can use pip show pyautogen to know from its print. In theconversable_agent.py, find the line (136) below which should be inside of __init__() function.
self.register_reply([Agent, None], ConversableAgent.check_termination_and_human_reply)Replace it with this line:
self.register_reply([Agent, None], ConversableAgent.a_check_termination_and_human_reply)3. Integrate it to the Panel UI
As usual, let’s now create the Panel ChatInterface.
First, initial the chat interface.
import panel as pn
pn.extension(design="material")
chat_interface = pn.chat.ChatInterface(callback=callback)
chat_interface.send("Send a message!", user="System", respond=False)
chat_interface.servable()Outgoing messages
The outgoing messages handling is the same as our previous demo. It simply registers a reply function for each agent to print them out to the Panel UI by using chat_interface.send() method which including the agent’s name, avatar and content.
avatar = {user_proxy.name:"👨💼", engineer.name:"👩💻", scientist.name:"👩🔬", planner.name:"🗓", executor.name:"🛠", critic.name:'📝'}
def print_messages(recipient, messages, sender, config):
chat_interface.send(messages[-1]['content'], user=messages[-1]['name'], avatar=avatar[messages[-1]['name']], respond=False)
print(f"Messages from: {sender.name} sent to: {recipient.name} | num messages: {len(messages)} | message: {messages[-1]}")
return False, None # required to ensure the agent communication flow continues
user_proxy.register_reply(
[autogen.Agent, None],
reply_func=print_messages,
config={"callback": None},
)
engineer.register_reply(
[autogen.Agent, None],
reply_func=print_messages,
config={"callback": None},
)
scientist.register_reply(
[autogen.Agent, None],
reply_func=print_messages,
config={"callback": None},
)
planner.register_reply(
[autogen.Agent, None],
reply_func=print_messages,
config={"callback": None},
)
executor.register_reply(
[autogen.Agent, None],
reply_func=print_messages,
config={"callback": None},
)
critic.register_reply(
[autogen.Agent, None],
reply_func=print_messages,
config={"callback": None},
) Incoming messages
Then we should focus on the implementation of the callback function which handles the incoming messages from the Panel’s input widget.
There are two logic paths for handling input messages:
the beginning message to start a session
the follow-up messages during the interim conversation
See the below code snippet for callback():
initiate_chat_task_created = False
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
global initiate_chat_task_created
global input_future
if not initiate_chat_task_created:
asyncio.create_task(delayed_initiate_chat(user_proxy, manager, contents))
else:
if input_future and not input_future.done():
input_future.set_result(contents)
else:
print("There is currently no input being awaited.")To release the runtime for the Panel widget, the callback should be defined as an async function.
The first input message will create a new thread
delayed_initiate_chat()to handle the entire AutoGen conversation asynchronously.From the second message, it will use the asyncio object
input_futureto pass the contents to Admin'sa_get_human_input()which we rewrote in the last step.
OK, now we should implement the delayed_initiate_chat() thread.
async def delayed_initiate_chat(agent, recipient, message):
global initiate_chat_task_created
# Indicate that the task has been created
initiate_chat_task_created = True
# Wait for 2 seconds
await asyncio.sleep(2)
# Now initiate the chat
await agent.a_initiate_chat(recipient, message=message)In this thread function, the entire conversation will be activated by agent.a_initiate_chat() from the user’s first message input.
4. Run the Web UI
Everything’s set, let’s get the wheels in motion!
Let’s consolidate the above code and run the server by the Panel command.
panel serve groupchat_research_2.pyWhen you receive something like below, that means the panel server is successfully running on the localhost with default port 5006. Visit this URL on your browser.
…
2023–11–13 18:26:25,470 Bokeh app running at:http://localhost:5006/
groupchat_research_2
…
Try to prompt any research topic to the group chat and meanwhile, don’t forget to respond to the agents in the conversation.